
Beyond Vibe Coding: A Multi-Agent Experiment
A collaborative exploration of using AI engineering personas to build quality systems

Almost two years ago, I wrote about The Era of Co-Pilot Product Teams, imagining a future where AI would sit alongside us as collaborative engineering partners. That future arrived—but it brought questions we didn't anticipate.
Over the past few weeks, I've been exploring whether we can use AI agents through various AI coding assistants (GitHub Copilot, Claude Code with Sub-agents) to build end-to-end business systems with proper engineering practices and quality controls. A goal was also to test the hype around the phenomenon coined by Andrej Karpathy as "vibe coding"—the practice of using AI to generate code through conversational prompts. The results have been... educational.
While vibe coding excels at rapid prototyping, it creates more technical debt than it solves. Our 72-hour experiment demonstrated a multi-agent approach can potentially reduce long-term technical debt by identifying security vulnerabilities and architectural problems during development—though it requires significant upfront investment in token costs, human oversight, and process discipline.
The code and patterns discussed here are my individual opinions and not affiliated to my employer or their customers. The code along with the engineering agents’ persona and IDE instructions are available on GitHub. This is experimental work—use with appropriate caution and contribute your own findings.
Why Vibe Coding Is Not Enough
⚙️❌ The Maintenance Reality
While vibe coding promises to invert the productivity equation—suddenly we're creating code at 10x speed—it often amplifies the maintenance and integration problems that plague enterprise AI. MIT's latest research The GenAI Divide reveals a stark disconnect between AI investment and enterprise value creation. The report found that despite $30-40 billion in enterprise investment into generative AI, 95% of organizations are getting zero return on their AI pilots. The research attributes AI pilot failures to "brittle workflows, lack of contextual learning, and misalignment with day-to-day operations".
💣 The Technical Debt Multiplication Effect
My experiments revealed that letting Claude or GitHub Copilot generate code without proper design, instructions, and continuous co-engineering with the assistant can result in:
Security vulnerabilities: 6 critical issues including exposed PII and missing authentication
Performance problems: rigid design choices, unbounded loops, no caching strategy
Reliability gaps: Lack of error handling, no retry logic, no circuit breakers
Observability blind spots: No structured logging, limited tracing
The same AI that generated functional code in minutes had created weeks of potential technical debt.
Vibe coding without quality controls can make the code-to-debt ratio even worse because the tech debt accumulates faster than human review can catch it.
🔻 Engineering Quality becomes a function of Prompt Quality
The most concerning aspect? Core engineering principles—security, observability, performance, reliability—now depend entirely on the effectiveness of your prompts and IDE instructions.
E(quality) = f (Prompt Instruction Quality)Take this real example from our experiment. AI assistants initially proposed using SSN (Social Security Number) as a primary key for loan applications, which created multiple problems: security violations (PII should never be logged), geographic limitations (SSN is US-specific), and compliance risks (violates data protection regulations). Only through spending considerable time personally examining the data models—did I catch this and redesign with UUID-based identifiers instead.
AI Proposed (Using SSN):
# loan_processing/models/application.py
class LoanApplication(BaseModel):
...
ssn: str = Field(
description="Social Security Number",
pattern=r"^\d{3}-\d{2}-\d{4}$" # Format: XXX-XX-XXXX
)
...
Human-Collaboration (Using applicant_id):
# loan_processing/models/application.py
class LoanApplication(BaseModel):
...
applicant_id: str = Field(
description="Applicant identifier (UUID format)",
pattern=r"^[a-fA-F0-9\-]{36}$", # UUID format: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
)
...
Without explicit instructions in your AI assistant configuration files (CLAUDE.md, GitHub Copilot instructions, etc.), AI assistants may not implement basic engineering requirements—input validation, authentication, error handling, proper logging, or performance optimization.
You're falling into the issue encoding your entire engineering culture into prompt instructions. Miss something in your prompt, and it's missing from your system. The quality of your software becomes directly tied to the quality of your AI instructions—a dependency that most teams aren't prepared for.
The result is a system that appears functional but is brittle and fragile, missing the defensive programming and operational considerations that distinguish prototype code from production systems.
The Experimental Approach: Using AI Agents to Reduce Vibe Coding Risks
Here's the hypothesis we tested: Instead of abandoning vibe coding—which remains valuable for rapid code generation, can we reduce the issues through systematic AI agent-based review lifecycle?
We employed 5 Engineering agents to collaborate in building an end-to-end loan processing system:
System Architecture Reviewer: Validates design decisions and system impacts during development
Code Reviewer: Ensures code quality and architectural alignment before commits
Product Manager Advisor: Aligns features with business value and requirements
UX/UI Designer: Validates user experience and interface design decisions
GitOps CI Specialist: Manages Git operations and CI/CD pipeline success
The goal was not to slow down development but to catch production-critical issues early. Think of it as AI pair programming where your partners are specialized AI agents, each bringing expertise in their domain.
The Results so far…
After 72 hours (see metrics below) of development using multi-agent patterns, here's what we learned:
What Multi-Agent Development Delivered:
Architectural problems surfaced during development — Design issues identified, and code refactored before they became technical debt.
Documentation stayed current — Agents ensured CI pipelines and docs evolved with the codebase.
Security vulnerabilities identified early — The reviewer agents flagged “some” issues when AI suggested using PII data, preventing hidden security issues.
GitOps workflow improved: The GitOps agent created GitHub Action and addition of Claude / GitHub Copilot as reviewer helped the CI pipeline.
What It Cost:
Token usage increased 5-15x — Every code generation became multiple specialized reviews with average token consumption of 8K-16K tokens.
Coordination overhead became significant — Managing five agents required constant orchestration of making sure they are aligned to the problem.
Diminishing returns on simple problems — Not every decision benefits from multiple AI perspectives, agents’ conversation can confuse each other.
Human intervention essential — Agents sometimes created circular discussion loops that required pattern-breaking by intervention (e.g. STOP, WAIT, don’t do this)
Critical caveat: The human must remain actively engaged throughout the entire lifecycle. Simply having AI agents write code and other AI agents review it is equally dangerous—you're just multiplying the same blind spots and biases across multiple AI systems. The human developer(s) provides pattern recognition, contextual judgment, and the ability to break out of AI solution loops that no amount of agent specialization can replace. You're not delegating engineering judgment; you're augmenting it with specialized AI perspectives while maintaining human oversight at every critical decision point.
For details of these development agent personas in action, see the complete engineering agents documentation and agent-based development approach in the GitHub repo. The decision records from this experiment are also available in the docs/decisions folder.
Human-AI Collaboration: Where did I invest my time?
The Setup:
Team Composition: 1 Human + 5 Specialized Engineering Agents
Sprint Duration: 72 hours over 12 days (~6 hours per day)
Repository Activity: Multiple PRs, systematic commits, and decision records
Test Coverage: 204 tests with 75% coverage achieved
Development Pattern: Small-batch commits with immediate testing and documentation
When building with AI agents, I spent ~7% of my time on actual code generation and refactoring. The other > 90% was engineering work that happens before, during and after the code.
The Full Development Story
When I started this experiment, I could have jumped straight into vibe coding—asking AI Assistant to "build a loan processing system." Instead, I spent the first many hours without writing a single line of code.
Business Understanding
I used Claude to analyze the loan processing market, structure a business case, and map customer jobs-to-be-done. We debated loan origination workflows, identified key differentiators, and validated assumptions. This wasn't coding—it was strategic thinking with AI as a thought partner.
A crucial part of this business analysis involved leveraging the UX/UI agent to translate the jobs-to-be-done framework into actual user workflows. We mapped how loan applicants, underwriters, and decision-makers would interact with the system. Based on these user journey insights, we created tailored system prompts for each of our business loan processing agents—the Intake Agent, Credit Agent, Income Agent, and Risk Agent—ensuring each agent's behavior aligned with real user needs and business processes.
The result? A clear understanding of what we were building and why, documented in business value documentation that would guide future technical decisions.
Critical distinction: this wasn't a replacement for actual UX research or design thinking interviews with real customers. Listening to customer problems and identifying their needs are core to successful product development and cannot—at least today—be replaced by AI agents. AI assistants can of course augment this process—helping analyze interview transcripts, identifying patterns across customer feedback, or generating hypotheses to test—but they cannot replace the human connection, empathy, and contextual understanding that comes from direct customer interaction. I used AI-generated business context only to provide realistic grounding for domain personas we were building not to validate whether we should build a loan processing system in the first place. That fundamental product-market fit question requires real humans talking to real customers.
This is one area where vibe coding provides value: Instead of static Figma designs or wireframes, AI can rapidly generate functional prototypes that demonstrate end-to-end user journeys. I created interactive loan application flows to simulate test concepts.
Metrics:
AI Collaboration: ~70% (strategic analysis, jobs-to-be-done mapping, rapid prototype generation)
Human Analysis: ~30% (synthesizing insights, validating business logic, documenting strategic decisions)
Key AI Value: Behaviour and domain validation, Rapid functional prototypes for testing
Human Value: Strategic synthesis and business validation that AI cannot replace
Setting up Engineering Agent(s) Infrastructure
Before I could even think about system architecture, I spent time set up what I call software-agent infrastructure. It involved crafting and iterating on developer-agent personas, writing detailed AI assistant configuration files, and configuring the development environment to work with specialized subagents that work for my domain and scenarios.
The real work was encoding engineering guardrails into personas—creating the System Architecture Reviewer, Code Reviewer, Product Manager Advisor, UX/UI Designer, and GitOps CI Specialist. Each persona needed specific expertise, decision-making criteria, and review patterns. I iterated through multiple versions, testing how different persona descriptions affected the quality of feedback. These will evolve over time.
A critical part of this setup was establishing the docs/decisions directory structure and configuring the AI assistant with explicit instructions to create Architecture Decision Records (ADRs) for every key design choice. I added specific instructions to ensure that whenever we made architectural decisions, the AI would automatically document them with context, alternatives considered, and consequences. This wasn't optional—it was baked into the framework from the start.
System Design with Agents
Once the agent infrastructure was configured, decision documentation was automated, and the AI assistant could reliably invoke these specialized personas, it came to design the architecture. I switched the development environment to a planning mode so we could evaluate architectural patterns before writing any code.
This was almost like white boarding ideas with another peer—we validated different approaches against business requirements to define a high-level architecture.
As an example, one of the planning discussions was determining the fundamental orchestration for the Loan Processing. Initially, I proposed a single orchestrator that would manually call each domain agent in sequence. But the System Architecture Reviewer agent challenged this approach, leading to one of the architectural decisions. The System Architecture Reviewer analyzed my business case and original design and recommended implementing proper agent handoff patterns where agents control their own workflow transitions rather than having a central orchestrator manage everything.
The architecture evolved from a single orchestrator calling all MCP servers to an autonomous agent chain with structured handoffs:
Original - Single Orchestrator Pattern:
Orchestrator
├─ MCP Server (Application Verification)
├─ MCP Server (Credit Assessment)
├─ MCP Server (Income Validation)
└─ MCP Server (Risk Analysis)
↓
Loan Decision
Evolved - Agent Chain with Handoff Pattern:
Application Input
↓
Intake Agent → MCP Server (Document Processing...)
↓ (structured handoff)
Credit Agent → MCP Server (Application Verification, Credit Assessment, ...)
↓ (structured handoff)
Income Agent → MCP Server (Application Verification, Income Assessment)
↓ (structured handoff)
Risk Agent → MCP Server (Financial Calculations, ...)
↓
Loan Decision Output
This architectural decision, documented in ADR-002: Agent Base Architecture and ADR-004: Agent Handoff Pattern Implementation, solidified our commitment for keeping the agents autonomous and separation of concerns.
We redesigned several times before writing much code, with each iteration guided by the architectural review feedback documented.
Metrics:
AI Collaboration: ~60% (persona development, architecture exploration, design iterations)
Human Decision-Making: ~40% (evaluating architectural trade-offs, making final design commitments, breaking recommendation loops)
Key AI Value: Rapid exploration of architectural patterns and systematic persona development
Human Value: Final architectural decisions and pattern-breaking when AI gets stuck in loops
Critical Insight: 3 complete redesigns needed - AI excels at iteration, human judgment essential for commitment
The Iterative Code Generation Process
Here's where vibe coding typically starts—and often ends. "AI, implement a loan processing agent." But I had learned the instruction approach needed to be robust and fine grained.
My instructions to the AI assistant were explicit:
code in small chunks, not large features.
Each implementation had to include comprehensive test suite updates.
The system was configured to regularly call in the System Architecture Reviewer and expert engineer agents throughout the coding process, not just at the end.
This led to a disciplined iterative workflow:
generate code → test → review → refine → commitThe gitops-ci-specialist agent ensured that only after this complete cycle would we move to the next feature. The CI pipeline was designed with specific GitHub Actions where all tests had to pass, expert reviewer agents had to approve, and I configured the AI assistant as an additional PR reviewer alongside human review.
Three critical instructions proved essential:
First, the AI was instructed to ensure documentation was always up to date with every change (more on this later).
Second, the AI assistant was instructed to learn from its mistakes and update its own instruction file—and synchronize those learnings across development environments (CLAUDE.md, GitHub Copilot instructions). This way I knew documentation stayed current and the AI was genuinely learning throughout the process.
Another critical part of this process was establishing disciplined version control patterns. The biggest mistake could be to make AI assistants see and modify entire repositories. It's like giving someone the keys to your house, your car, and your bank account because they offered to water your plants. I avoided this with frequent commits and focussing on small features.
Metrics (Time Spent):
Actual Code Generation: ~20% (AI writing implementation code)
AI Review & Testing: ~35% (agent discussions, code review cycles, test iterations)
Human Orchestration: ~30% (breaking solution loops, architectural guidance, decision-making)
CI/CD & Debugging: ~15% (GitHub Actions issues, pipeline configuration)
Key AI Value: Rapid code generation and systematic multi-perspective review
Human Value: Pattern recognition, breaking AI loops, maintaining development velocity
Critical Interventions: Multiple instances where human pattern-breaking was essential to prevent AI solution loops
Here's what multi-agent development looks like using Claude Code with Sub-agents—a continuous conversation where I'm part conductor, part translator, part skeptic:
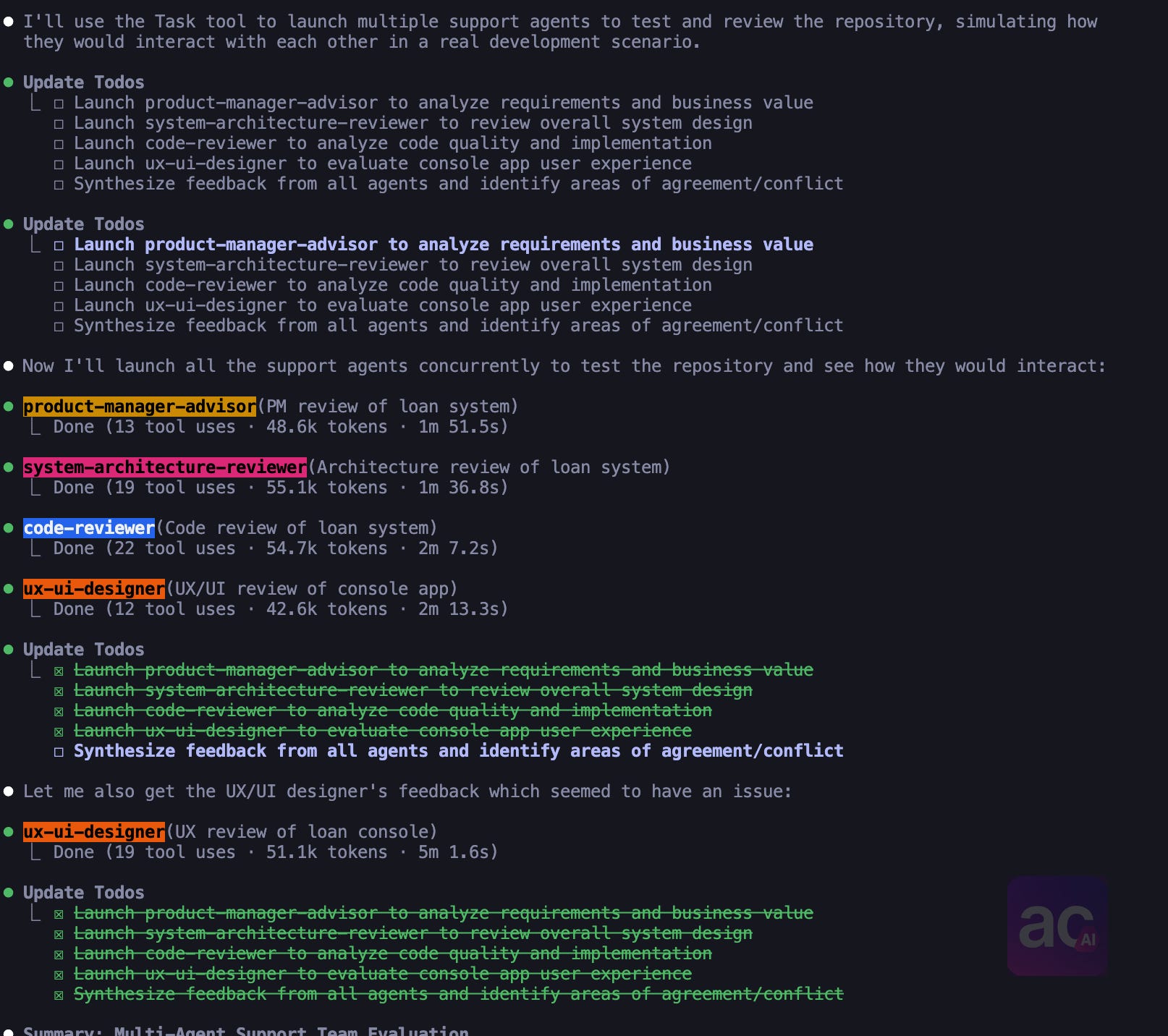
Key Learnings: What Works, What Doesn't, and What I Am Still Figuring Out
Documentation as AI Memory System
The most undervalued practice in AI-assisted development: Not treating documentation as the AI's memory system. AI assistants have limited persistent memory across sessions—your documentation becomes a good way to understand project context.
Essential practices for AI collaboration resilience:
Expressive commit messages: Explain the "why" behind every change, not just the "what"
Detailed PR descriptions: Include context, alternatives considered, and decision rationale
Living specifications: Keep documentation fresh and reflective of current system state
Decision records: Document architectural choices with full context for future AI sessions
Real-world Experience: When Claude Code terminal shut down mid-development or when GitHub Copilot switches contexts, restarting with quality documentation allowed immediate context recovery and continued productive collaboration. Although Claude and Github Copilot does store conversations locally they are limited by the disk capacity, without this documentation foundation, every session restart means starting over from scratch.
Building Agents Engineering Memory
Every significant decision became an ADR (Architecture Decision Record). Not because it's best practice, but because with major refactoring I kept forgetting why we made certain choices over time. For example, we documented why we chose UUID-based application IDs over SSN identifiers—a decision that can be a compliance nightmare without proper documentation.
PR Reviews Are Already Too Late
Traditional thinking: "We'll catch issues in PR review."
Reality in the age of vibe coding: By the time you're reviewing a PR with 2,000 lines of AI-generated code across 20 files, it's too late. The context is lost. The decisions are baked in. The technical debt is already accumulated.
The intervention points that actually worked:
Before generation: Constrain what the AI can see and modify
During generation: Active dialogue and questioning
After each chunk: Immediate testing and validation
Before commit: Review and document decisions
After commit: Run full test suite
PR review becomes confirmation, not discovery.
The Testing Reality
AI assistants initially generated tests that achieved 95% coverage—impressive until you realized they were mostly mocking everything and testing nothing. When tests failed, the AI's first instinct was to disable them, not fix them. This revealed a critical pattern:
When pushed to "make it work," AI assistants take the path of least resistance—even if that means compromising the very checks meant to ensure quality. It took human intervention to insist on tests that actually validated business logic.
Token Cost Multiplication
While you can use AI to generate system prompts and agent persona, they usually end up in long instructions that can be repetitive and bloat the prompt itself. When Claude or GitHub CoPilot processes these instructions, you start seeing the consumption going significantly up.
Example calling the system architect and code reviewer agent on average consumed 50K or more tokens depending on the complexity.

The multi-agent approach might increase token usage to 5-15x compared to chat conversation development. You need to refine your instructions to make sure that every code generation request does not require multiple specialized reviews, avoiding significant API cost implications for larger projects.
Cost-Benefit Analysis Reality with Development Agents:
Token usage: 5-15x increase over chat agent and requires careful budget planning
Quality improvement: Significant for complex systems, minimal for simple scripts
Development time: Slower for individual proof of concepts, faster for avoiding long-term technical debt.
Maintenance savings: Better quality code should result in lower maintainability costs; however, the long-term benefits require more data to measure benefit.
Agent Overhead Complexity
Managing five specialized agents (or more) requires careful orchestration. Agents can create circular discussion loops without human intervention—for instance, the Architecture Reviewer might suggest a pattern that the Code Reviewer questions, leading to back-and-forth that never reaches resolution without human pattern-breaking. With multiple specialized perspectives weighing in on every decision, simple problems can become over-engineered. A basic validation function might trigger architectural discussions when a straightforward implementation would suffice.
The Journey has just begun…
Vibe coding has proven its value for prototyping and exploration. The challenge is adapting it for production systems without losing the speed benefits.
My experiments with multi-agent development offers one approach: using specialized agent personas to provide systematic review during development, catching issues that typically only surface in production. This maintains rapid development for appropriate use cases while adding quality gates for production code.
What I am Still Figuring Out
Optimal Agent Granularity: How specialized should each agent be?
Context Management: How much context should agents share?
Human Intervention Points: When is human judgment essential vs optional?
Cost-Benefit Analysis: Which use cases justify the increased token usage?
Pattern Recognition: How do we detect and break agent discussion loops?
This isn't a solved problem. It's an ongoing experiment in balancing speed with quality.
Message for Technical Leaders
Starting Your Own Experiments: if you're interested in exploring multi-agent patterns my recommendations would be to start small, learn and grow:
Pick a non-critical project for experimentation
Define 2-3 agent personas based on your team's expertise
Measure specific quality metrics (bug rates, security issues, architectural violations)
Document what works and what doesn't
Feel free to use my learnings and agent-persona as starting points. The code and patterns discussed here are available at GitHub Repository. The complete methodology is documented in our agent-based development guide. This is experimental work—use with appropriate caution and contribute your own findings.
Happy Building ;)